Table of Contents
What is Data Clustering?
Data Clustering is the process of sorting and distribution of data within partitions based on a clustering key.
As we know partition pruning is the way to eliminate unwanted micro-partition scanning for a query with a where clause. This is achieved because snowflake maintains the data in partition in a columnar storage and all the metadata of partitioning is maintained. Hence snowflake automatically determines which column to be picked from which partition.
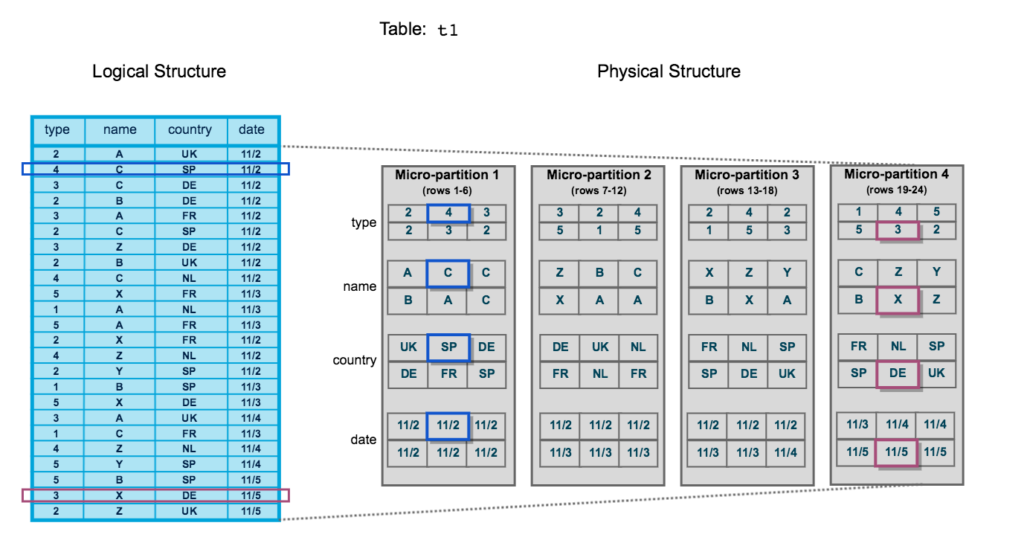
Snowflake partitions the data as it arrives in partitions and hence when the data grows (especially for large tables) the values of a column can be scattered across the multiple partitions creating non uniform or non contiguous partitions. In such cases, snowflake query may not perform well. To address such issue, a key can be defined as a clustering key which distributes the data, sorts the data in well manner. Lets take an example below for data clustering.
Ref. Snowflake Website
In the above example, the date is clustering key and hence data is sorted across partitions providing pruning and performance benefit.
Clustering Information Maintained for Micro-partitions
Snowflake maintains data clustering metadata information for partitions:
- The total number of micro-partitions in a table
- The number of micro-partitions containing values that overlap with each other (in a specified subset of table columns).
- The depth of the overlapping micro-partitions.
Clustering Depth
Clustering depth is the degree to which the data is overlapping between multiple micro partitions. Lower the clustering depth, better the data distribution and hence better is the clustering.
Clustering depth can be used for a variety of purposes, including:
- Monitoring the clustering “health” of a large table,
- Determining whether a large table would benefit from explicitly defining a clustering key.
A table with zero micro partitions has zero clustering depth. Please check the below example for clustering depth explanation.
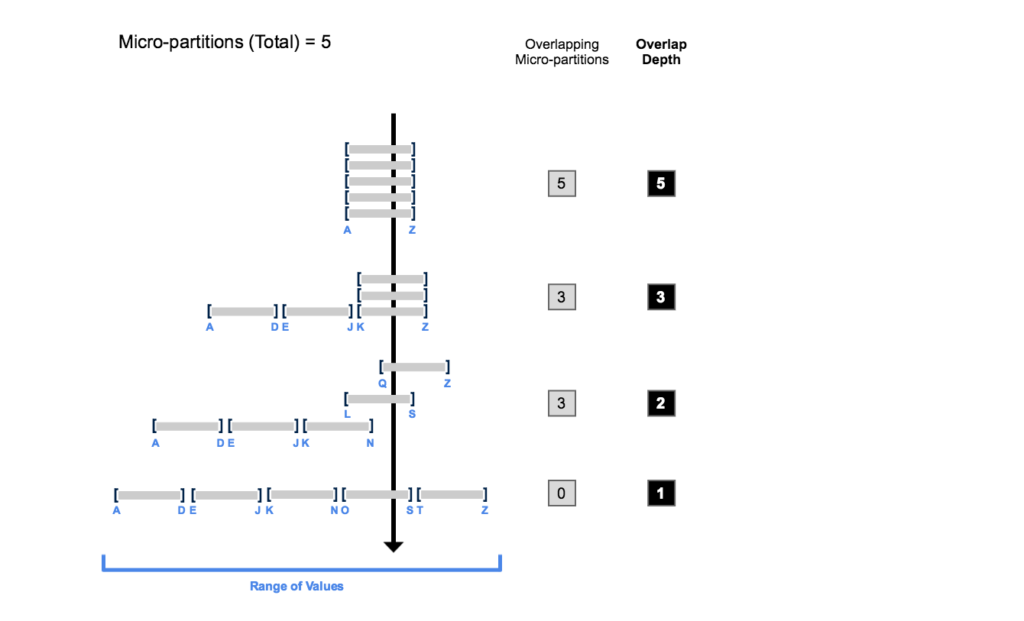
- Initially, there is overlap among the range of values in all micro-partitions.
- As the quantity of overlapping micro-partitions diminishes, the depth of overlap decreases correspondingly.
- When there is no longer any overlap in the range of values across all micro-partitions, they are deemed to be in a static state (i.e., unable to benefit from further clustering).
Suitable Candidate for Clustering?
- Large table with large no of partitions
- table with frequent access of small portion of data
- table with frequent where clause or sorted data access
A clustering key which is mostly used in where condition or sort columns or group columns or join columns should be selected.
Re-clustering
Re-clustering may be needed if the table becomes less clustered after certain period due to DML operations or data loading.
Reclustering in Snowflake is automatic; no maintenance is needed.
Automatic Clustering
Automatic Clustering is the service provided by Snowflake that effortlessly and consistently handles all reclustering requirements for clustered tables.
It’s important to note that once a clustered table is defined, re-clustering may not commence immediately. Snowflake initiates re-clustering for a clustered table only when it stands to gain significant benefits from the process.